



Describir el desarrollo de un sistema de información que conecta datos procedentes de múltiples registros, sanitarios y otros, para su uso con fines asistenciales, de administración, gestión, evaluación, inspección, investigación y salud pública.
MétodoConexión determinística de datos pseudonimizados de una población de 8,5 millones de habitantes, procedentes de Base de datos de usuarios, Historia clínica electrónica DIRAYA, Conjunto mínimo básico de datos (hospitalización, cirugía mayor ambulatoria, urgencias hospitalarias y hospital de día médico) y sistemas de información de salud mental, pruebas de imagen, pruebas analíticas, vacunas, pacientes renales y farmacia. Se utilizó un codificador automático para los diagnósticos clínicos y se definieron 80 enfermedades crónicas para su seguimiento. La arquitectura del sistema de información constó de tres capas: datos (base de datos Oracle 11g), aplicaciones (MicroStrategy BI) y presentación (MicroStrategy Web, librerías JavaScript, HTML 5 y hojas de estilo CSS). Se implantaron medidas para la gobernanza del sistema.
ResultadosSe incluyeron datos de 12,5 millones de personas que fueron usuarias entre los años 2001 y 2017, con 435,5 millones de diagnósticos. El 88,7% de estos diagnósticos fueron generados por el codificador automático. Los datos se presentan mediante informes predefinidos o consultas dinámicas, ambos exportables a ficheros CSV para su tratamiento fuera del sistema. Analistas expertos pueden acceder directamente a las bases de datos y realizar extracciones mediante SQL o tratar directamente los datos con herramientas externas.
ConclusiónEl trabajo ha mostrado cómo la conexión de registros sanitarios abre nuevas posibilidades en el análisis de datos.
To describe the development of an information system that connects data from multiple health records to improve assistance to patients, health services administration, management, evaluation, and inspection, as well as public health and research.
MethodDeterministic connection of pseudonymized data from a population of 8.5 million inhabitants provided by: a users database, DIRAYA electronic medical records, minimum basic data sets (inpatients, outpatient mayor surgery, hospital emergencies and medical day hospital), mental health information systems, analytical and image tests, vaccines, renal patients, and pharmacy. An automatic coder was used to code clinical diagnoses and 80 chronic pathologies were identified to follow-up. The architecture of the information system consisted of three layers: data (Oracle Database 11g), applications (MicroStrategy BI) and presentation (MicroStrategy Web, JavaScript libraries, HTML 5 and CSS style sheets). Measures for the governance of the system were implemented.
ResultsData from 12.5 million health system users between 2001 and 2017 were gathered, including 435.5 million diagnoses, 88.7% of which were generated by the automatic coder. Data can be accessed through predefined reports or dynamic queries, both exportable to CSV files for processing outside the system. Expert analysts can directly access the databases and perform queries using SQL or directly treat the data with external tools.
ConclusionThe work has shown that the connection of health records opens new possibilities for data analysis.
La digitalización de los servicios sanitarios está generando un volumen de datos sin precedentes, tanto para la atención sanitaria como para su uso secundario1,2.
En el Sistema Sanitario Público de Andalucía (SSPA), la historia clínica electrónica y otros sistemas de información generan datos cuya explotación se realiza en módulos específicos de tratamiento, creándose silos independientes de datos; esta misma evolución ha sido observada en otras organizaciones3.
Tal fragmentación de datos crea duplicidades, propicia su infrautilización y afecta a su calidad y costes de gestión. Esta situación está evolucionando hacia modelos de análisis más globales, gracias a la conexión de registros y la interoperabilidad de los sistemas de información4. La integración de datos produce sinergias que aumentan su valor, y genera un conocimiento superior al obtenido a partir del análisis aislado e independiente de cada sistema de información.
La conexión de registros es habitual en proyectos de investigación específicos, pero lo es menos como actividad continuada, sistemática e institucional, para el uso secundario de datos administrativos. Estas iniciativas institucionales suelen tener como finalidad la evaluación de políticas públicas5 o el desarrollo de infraestructuras para investigación social6, si bien tendrán cada vez mayor relevancia como apoyo a estrategias nacionales de inteligencia artificial7.
La integración de datos con fines gerenciales (business intelligence) en el sector de la salud es limitada4,8, situación que previsiblemente se verá modificada por el interés creciente en el uso secundario de los datos sanitarios9. En este contexto, el SSPA puso en marcha un proyecto de «gobernanza de datos»10 para superar las dificultades que se encuentran en la gestión de datos dispersos en los múltiples sistemas de información y contribuir a una mejora de la atención sanitaria, al ayudar a la toma de decisiones en un entorno cada vez más complejo.
El objetivo de este trabajo es describir el desarrollo del sistema de información que conecta datos procedentes de diferentes silos de información del SSPA y de otras fuentes externas, para su uso con fines asistenciales, de administración, gestión, evaluación, inspección, investigación y salud pública11.
MétodoEl proyecto contó con una dirección y un comité director situados al máximo nivel de la organización para garantizar su gobernanza (planificación, seguimiento y gestión); contó además con un comité técnico de seguimiento y grupos de apoyo para aspectos específicos11.
Se conectaron de forma determinística registros de los 8,5 millones de personas cuya asistencia sanitaria es cubierta por el SSPA. El identificador de cada persona fue el número único de historia de salud de Andalucía que figura en la base de datos de usuarios del SSPA12.
El sistema de información conectó, para cada persona, datos individuales obtenidos de los siguientes sistemas de información corporativos:
- •
Base de datos de usuarios del SSPA.
- •
Historia clínica electrónica (DIRAYA).
- •
Sistema de información de salud mental.
- •
Conjunto mínimo básico de datos (CMBD): hospitalización, cirugía mayor ambulatoria, urgencias hospitalarias y hospital de día médico.
- •
Sistema de información de vacunas.
- •
Sistema de información de pacientes renales.
- •
Pruebas de imagen.
- •
Pruebas analíticas.
- •
Sistema de información de farmacia (parcialmente).
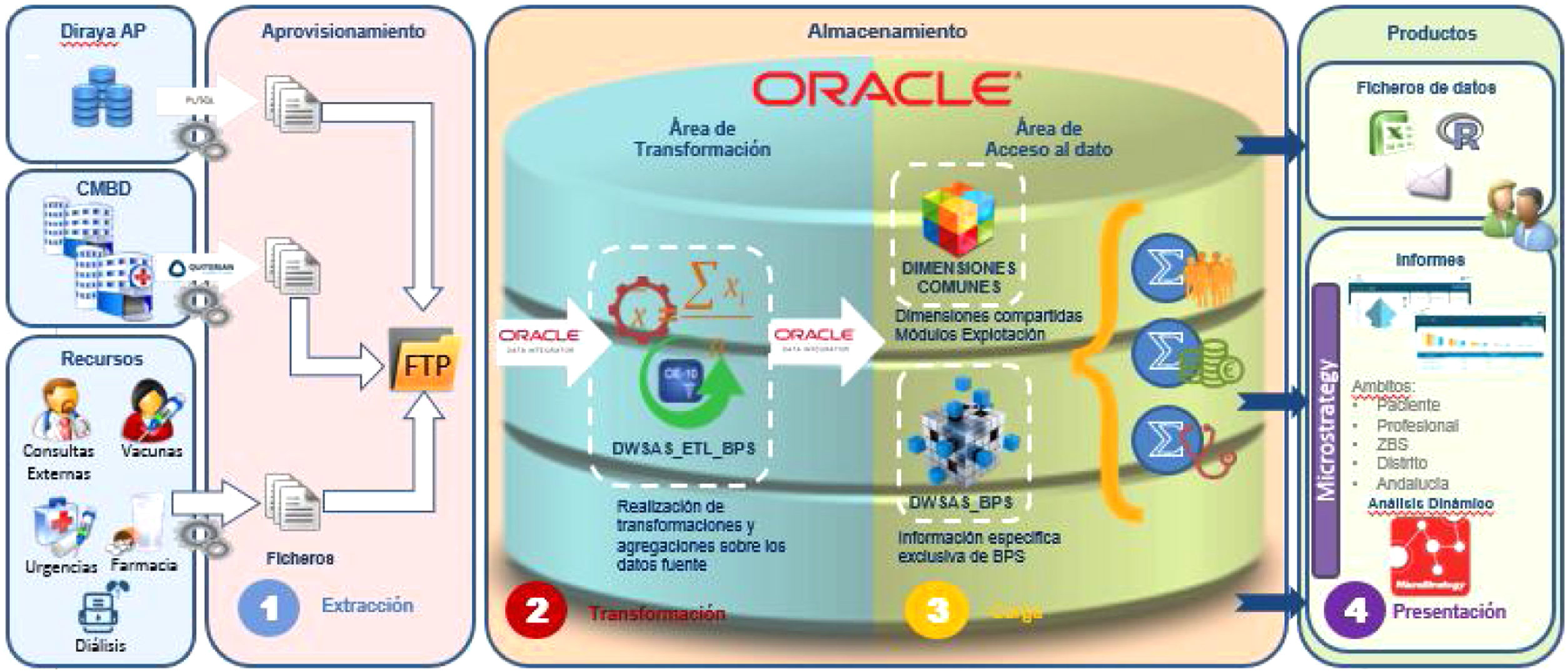
El sistema se desarrolló con una arquitectura en tres capas: capa de datos con servidor de base de datos Oracle 11g, capa de aplicaciones en MicroStrategy BI y capa de presentación con utilidades de MicroStrategy Web, librerías JavaScript, HTML 5 y hojas de estilo CSS (fig. 1).

En los procesos ETL (Extract, Transform and Load), los datos fueron extraídos de sistemas operacionales o de ficheros externos, depositados en un servidor FTP y cargados en la base de datos Oracle, tras controles de recepción y detección de inconsistencias. En el proceso de transformación, los datos fueron enriquecidos para facilitar su explotación, realizando operaciones de codificación de diagnósticos, aplicación de reglas de negocio, agrupación de casos (Adjusted Clinical Groups)13 y grupos de morbilidad ajustados14, y cálculo de indicadores. Los datos se cargaron en un modelo de datos en estrella, modelo dimensional, y tablas agregadas que alimentan cubos inteligentes de MicroStrategy para favorecer su explotación y rendimiento.
Los diagnósticos clínicos fueron codificados por documentalistas clínicos para los CMBD de hospitalización, cirugía mayor ambulatoria y hospital de día médico, y mediante un codificador automático de desarrollo propio para urgencias hospitalarias e historia clínica electrónica de atención primaria15. Para la codificación se utilizó la modificación clínica de la Clasificación Internacional de Enfermedades (CIE), tanto la novena versión española de la CIE-9-MC de 2014 como las dos primeras versiones CIE-10-ES (2016 y 2018). Los diagnósticos de atención primaria se obtuvieron de DIRAYA, de los apartados «Motivo de consulta», «Problemas de salud», «Programas» y «Procesos».
Se estableció una lista de enfermedades crónicas para su seguimiento («patologías BPS») tomando como referencia los grupos de la clasificación CCS (Clinical Classifications Software) elaborados por el HCUP (Healthcare Cost and Utilization Project)16, que agrupan los códigos CIE en un número de categorías con significado clínico útiles para presentar estadísticas descriptivas. Se utilizó el Chronic Condition Indicator de HCUP para establecer si un diagnóstico representaba una enfermedad crónica, y se añadió un atributo propio indicando si la cronicidad era permanente o limitada en el tiempo.
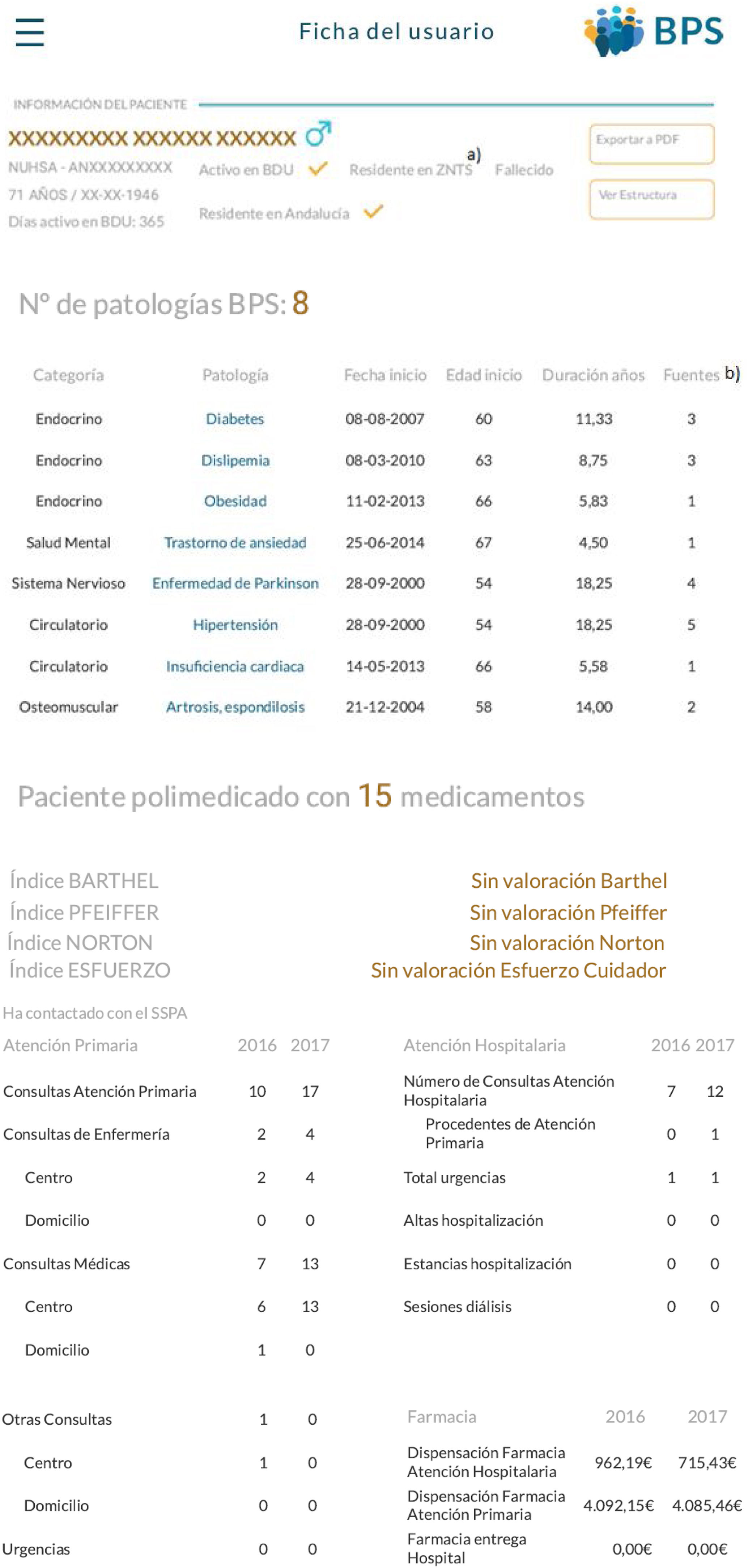
De DIRAYA atención primaria y hospitalaria se obtuvieron diagnósticos de enfermería (NANDA, NIC, NOC) y valoraciones funcionales (Barthel) y cognitivas (Pfeiffer y otras).
Los indicadores de prevalencia, expresados como proporciones, se calcularon para periodos anuales de calendario, utilizando como numerador el número de personas-día que presentaron una condición y como denominador el total de personas-día en seguimiento durante el periodo17. Para la comparación de la prevalencia entre distintos ámbitos se calculó la razón estandarizada de prevalencia y su intervalo de confianza.
A cada paciente se le aplicaron los costes unitarios de cada servicio recibido, obtenidos del sistema de contabilidad analítica COAN SSPA18.
Los pacientes se asociaron a las claves médicas y de enfermería de los profesionales de atención primaria que los atienden, agrupando los resultados por profesional y centro de atención primaria, unidad de gestión clínica, distrito sanitario y Andalucía.
Se configuró un acceso para las personas autorizadas, con identificación y autenticación segura desde la Red Corporativa de la Junta de Andalucía, limitado a los datos necesarios para el ejercicio de sus funciones específicas. En su desarrollo se tuvieron en cuenta las medidas de seguridad y de protección de datos previstos por la legislación vigente.
ResultadosContenido del sistemaLa población incluida en el sistema representaba el 99% de la cifra oficial de población de Andalucía a 31 de diciembre de 2017. De forma acumulada, se incluyeron datos de 12,5 millones de personas que estuvieron dadas de alta en la base de datos de usuarios en algún momento entre los años 2001 y 2017, con un total de 435,5 millones de diagnósticos:
- •
347 millones procedentes de atención primaria desde 2001.
- •
49 millones procedentes de 8,7 millones de altas del CMBD de hospitalización y de 2,5 millones de altas de cirugía mayor ambulatoria desde 2001.
- •
37 millones procedentes de 27 millones de altas del CMBD de urgencias desde 2009.
- •
2,5 millones procedentes de consultas externas de salud mental desde 2014.
El 88,7% de estos diagnósticos fueron generados por el codificador automático, y el resto por los servicios de documentación hospitalarios.
También se incorporaron:
- •
911.000 valoraciones funcionales y 536.000 valoraciones cognitivas desde el año 2014.
- •
12 millones de diagnósticos de enfermería desde 2004.
- •
35,5 millones de actos vacunales desde 2000.
- •
12 millones de pruebas radiológicas (excepto radiología simple) desde 2014.
- •
35 millones de resultados de pruebas analíticas desde 2014.
- •
3 millones de constantes (peso, talla, índice de masa corporal, presión arterial) desde 2016.
Al aplicar la contabilidad analítica a las prestaciones recibidas por cada persona incluida en nuestro trabajo se explicó el 91,28% del presupuesto del SAS.
En esta fase inicial, la periodicidad de carga de las fuentes de información fue anual y la unidad temporal de presentación de datos fue el año-calendario.
El sistema ha alcanzado la cifra de más de 300 usuarios con perfil de gestión y salud pública, que forman parte de una comunidad de usuarios en la Red Profesional de la Junta de Andalucía. Para estos usuarios, los datos identificativos de los pacientes están enmascarados. Se ha comenzado la apertura del sistema a los profesionales asistenciales de atención primaria con acceso a los datos nominales de sus pacientes como apoyo a la gestión asistencial.
Utilidades de acceso a los datos- 1)
Informes predefinidos
Se elaboraron informes predefinidos para cada nivel de usuarios (médico o enfermera, centro de atención primaria, unidad de gestión clínica, distrito y Andalucía).
El sistema permite a los usuarios visualizar los informes propios de su ámbito y navegar, en su caso, a los de niveles inferiores. Los profesionales asistenciales pueden acceder a una ficha que incluye toda la información disponible de cada uno de sus pacientes (fig. 2).

Los listados predefinidos están agrupados en varias dimensiones que incluyen, entre otras:
- •
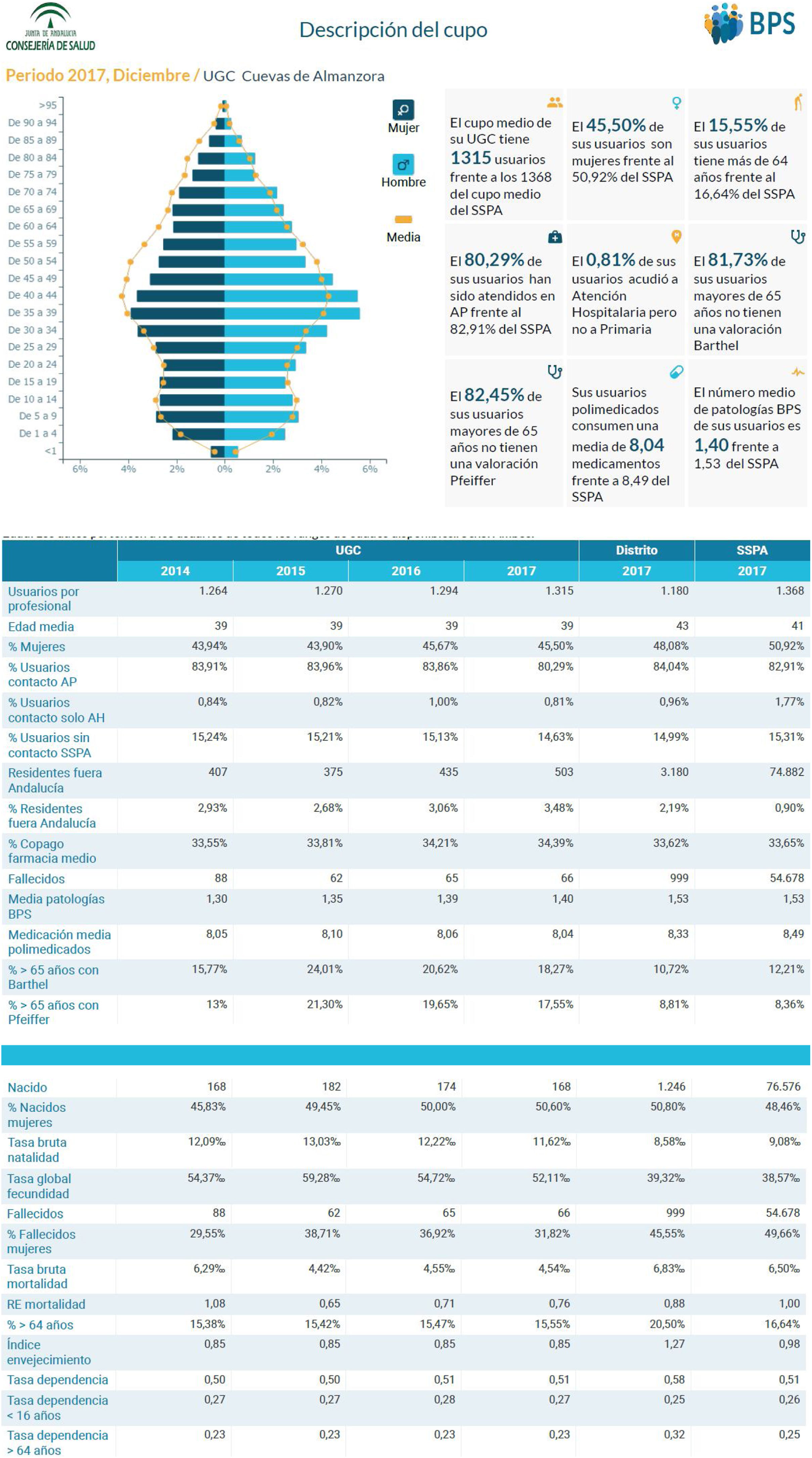
Características de la población: pirámide por edad y sexo, características demográficas, contacto con los servicios sanitarios, valoraciones funcionales, patologías crónicas o polimedicación (fig. 3).
- •
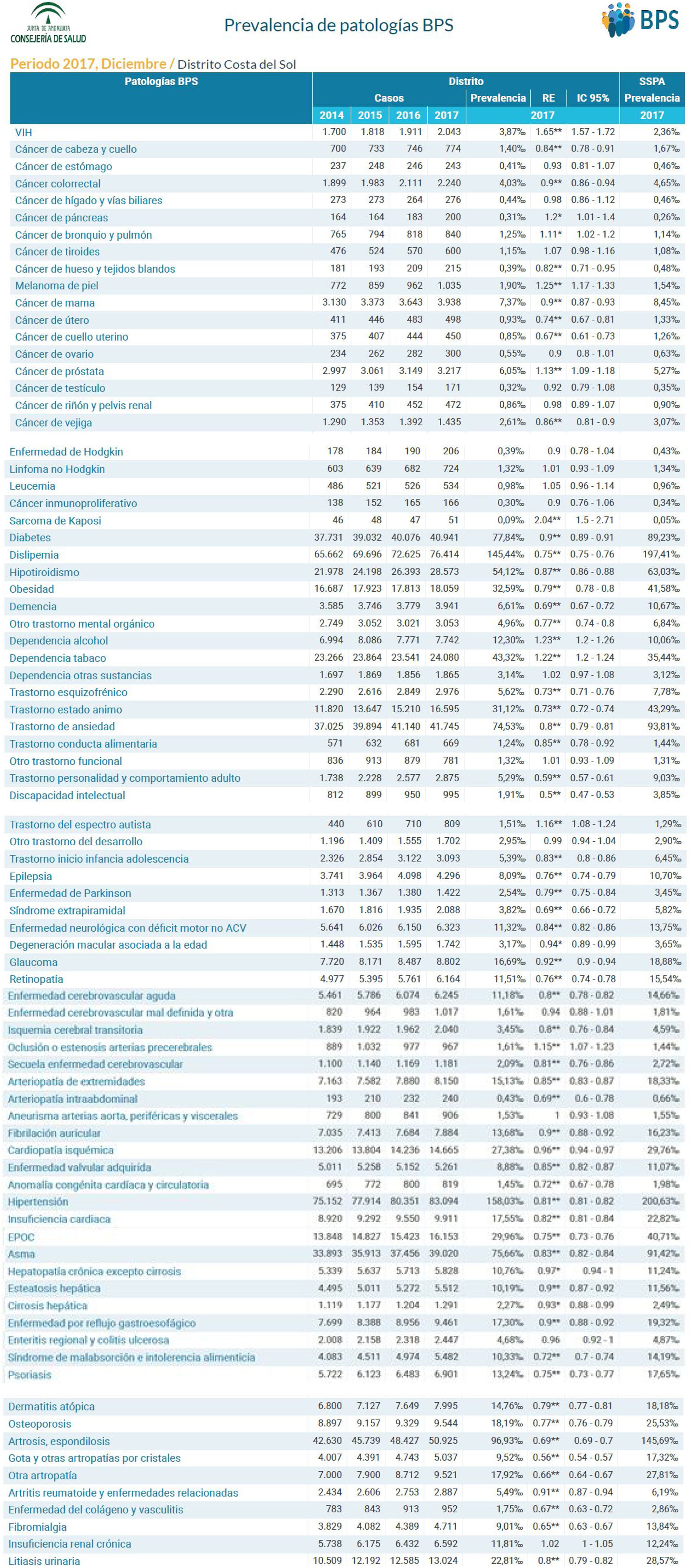
Prevalencia de enfermedades crónicas, su evolución temporal, razón estandarizada e intervalo de confianza (fig. 4).
- •
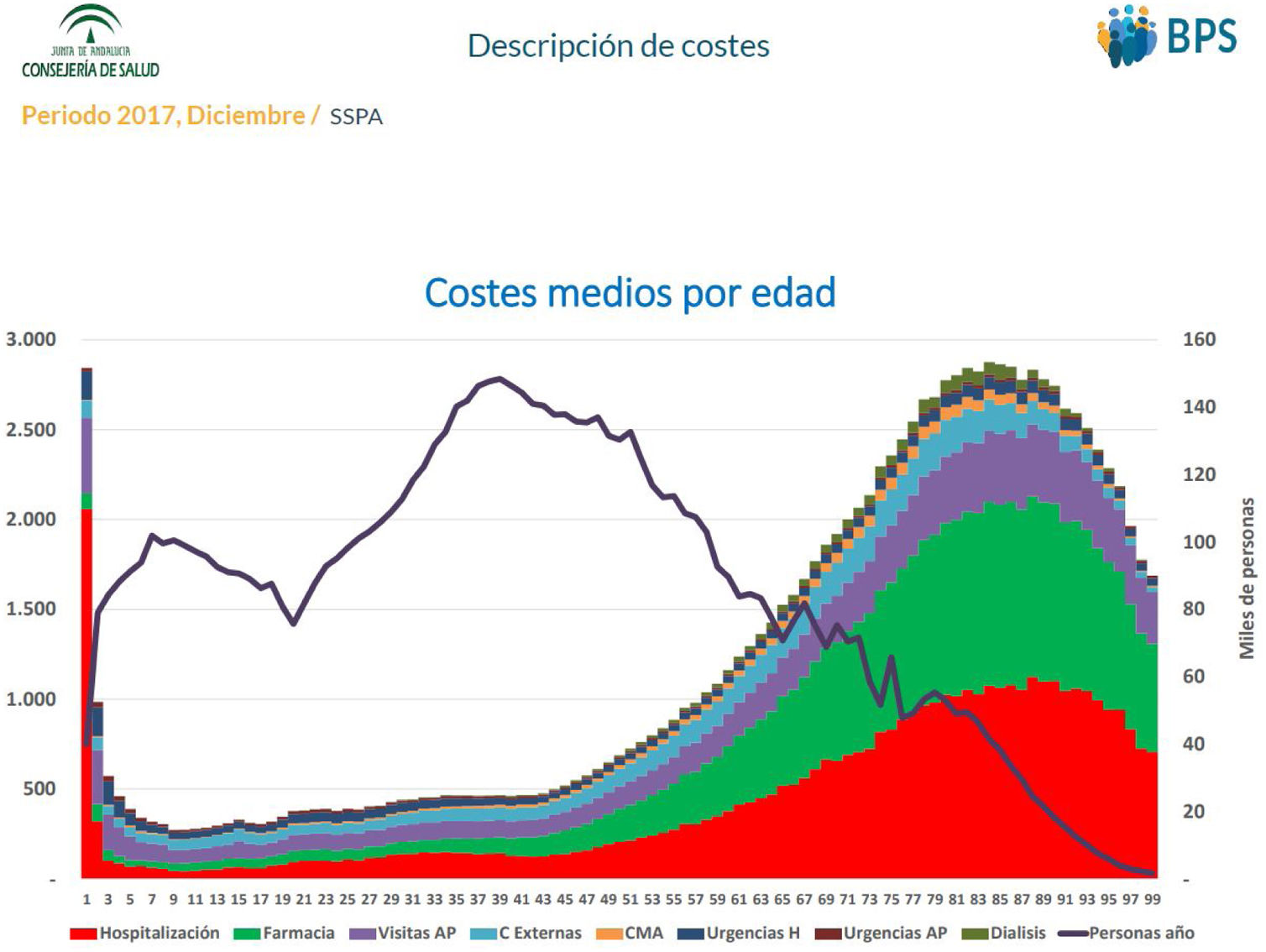
Uso de recursos, incluyendo la evolución del número de consultas y urgencias, los costes totales y los de servicios específicos por grupos de edad y sexo (fig. 5).



- 2)
Consultas dinámicas
Los profesionales sanitarios, según su perfil, pueden realizar mediante MicroStrategy determinadas consultas dinámicas. Ello les permite elegir conjuntos de variables para la selección de pacientes (sexo, grupo de edad, número y tipo de patologías BPS, etc.), de los cuales se muestra su identificación y la información clínica y administrativa más relevante disponible en el sistema.
Un grupo más reducido de usuarios de perfil avanzado puede realizar, también mediante MicroStrategy, consultas dinámicas utilizando todas las variables contenidas en el modelo de datos.
- 3)
Análisis de datos
Tanto los informes predefinidos como los resultados de las consultas dinámicas son exportables a ficheros CSV para su tratamiento fuera del sistema.
Usuarios expertos en análisis y explotación de datos, en el nivel central del SSPA, pueden acceder directamente a las bases de datos y realizar extracciones mediante SQL o tratar directamente los datos con lenguaje R u otros.
DiscusiónAunque el proyecto no es novedoso desde la perspectiva tecnológica, supone un avance importante en la gobernanza de datos en un servicio regional de salud. Nos permite adentrarnos en los retos19–21 y las limitaciones del Big Data22, que nos facilitará la incorporación de datos desde la web y las redes sociales, los análisis prescriptivos y predictivos, y la toma de decisiones por sistemas expertos23. Esta publicación no solo contribuye a aumentar la limitada producción científica8 en este campo, sino también a la transparencia acerca del uso de los datos sanitarios en las instituciones.
Evolucionaremos, por tanto, a un ecosistema de datos en el que coexistan los entornos BigData24 con los actuales Data Warehouse, sus sistemas de reporting y el análisis directo sobre bases de datos relacionales. Estos sistemas tradicionales continuarán teniendo importancia en el futuro, ya que seguirán resolviendo necesidades básicas de la mayoría de los usuarios.
El sistema que hemos implantado permite reconstruir la biografía sanitaria de las personas, y abre posibilidades de análisis longitudinal para la planificación, la gestión y la investigación sanitarias. Además, puede ayudar a la toma de decisiones en los ámbitos estratégico (planes y estrategias), de mesogestión (contratos programa) y microgestión (gestión clínica), con la facilidad de uso de los informes con indicadores predefinidos, y la autonomía del análisis dinámico de datos. Dado que el SSPA presta atención a la mayoría de la población andaluza, podemos considerar que la cobertura del sistema es poblacional.
Hay que destacar que las fuentes de información sobre actividad asistencial han sido incorporadas al sistema casi en su totalidad, lo que se ha puesto de manifiesto al aplicar la contabilidad analítica a cada una de las personas incluidas en el sistema.
Falta por incorporar al sistema información diagnóstica de consultas externas (salvo salud mental), hospital de día médico, urgencias de atención primaria, anatomía patológica, rehabilitación y farmacia (parcialmente). Igualmente, queda por desarrollar la conexión de BPS con otros registros sanitarios (metabolopatías, cáncer, virus de la inmunodeficiencia humana, voluntades anticipadas, etc.).
La incorporación de registros ajenos al SSPA, que no usan el número único de historia de salud de Andalucía como indicador individual, supone un reto importante. En este sentido, se está avanzando en el cruce sistemático de datos entre la base de datos de usuarios y el Registro de Población de Andalucía para incorporar, con fines estadísticos, datos demográficos, sociales y económicos de la población.
El proyecto ha puesto de manifiesto las dificultades en el desarrollo de Data Warehouse y Business Intelligence25,26; por una parte, los procesos ETL desde los sistemas operacionales son caros, complejos y lentos, requieren constantes adaptaciones al cambiar la disponibilidad o la necesidad de datos, y resulta difícil el mantenimiento de las tablas maestras que dan servicio a los sistemas operacionales y de explotación de datos. Además, aunque disponemos de cierto conocimiento acerca de la calidad de los datos del CMBD de hospitalización y urgencias y el proceso de codificación automática, es un aspecto a profundizar15,27–29. A medida que profundicemos en el uso de los datos nos podremos encontrar inconsistencias debidas al elevado número de fuentes y profesionales involucrados en la generación de información y a la falta de uniformidad en los criterios de recogida y codificación o en su aplicación.
Por otra parte, se detectan reglas de negocio escasamente definidas o aplicadas desigualmente en los distintos sistemas operacionales. Estos últimos deben mejorar su diseño y reforzar los controles de calidad en la recogida de datos.
Uno de los retos del sistema es la pronta devolución de la información generada a los usuarios finales. Los tiempos de disponibilidad están siendo acortados, y para algunas fuentes se actualiza trimestralmente. El objetivo es que la periodicidad de generación de la información sea mensual, si bien algunos indicadores de funcionamiento deberían estar disponibles prácticamente en tiempo real, lo que requiere nuevos abordajes metodológicos y tecnológicos.
La reproducibilidad es una limitación importante en los estudios a partir de registros debido a diferencias conceptuales y metodológicas; por ejemplo, para identificar las patologías y su duración. Si bien su efecto puede ser limitado en las comparaciones en el interior del SSPA, puede ser importante al comparar distintos sistemas sanitarios. Así, las prevalencias de enfermedades crónicas obtenidas a partir de nuestros datos son superiores a otras, debido probablemente a que nuestra metodología de extracción de diagnósticos desde las distintas fuentes de información es más exhaustiva.
Respecto a la gobernanza de los datos, nos hemos encontrado con los retos previamente descritos30–32 acerca de modelos organizativos para la gestión y análisis de datos, seguridad y privacidad, y gestión de tablas maestras y metadatos. Aunque el proyecto se ha desarrollado en una organización con un nivel de gobernanza avanzado, los avances en su gobernanza dependerán de los que se produzcan en el SSPA, reforzándose el liderazgo de la gestión y análisis de datos.
El proyecto ha sido contemporáneo con el Reglamento General de Protección de Datos (RGPD), cuyos principios incorpora, aunque es preciso profundizar en múltiples aspectos, en especial en los relativos a protección de datos en el diseño del sistema y los procedimientos de tratamiento de datos para su uso por terceros, sobre todo en el ámbito de la investigación.
Con respecto al perfil de los usuarios, está bien identificado el del usuario final de informes o consultas dinámicas, que no requiere formación avanzada en análisis de datos. Parece adecuado, en el marco de equipos multidisciplinarios, potenciar el perfil de analista de datos; haciendo una similitud con el perfil en Population Data Science33, este perfil incorporaría competencias en informática, análisis de datos y conocimiento de la población. En nuestro caso, desde la perspectiva poblacional y sanitaria, necesitaríamos profesionales capaces de combinar y analizar grandes bases de datos de diferente origen, identificar patrones y desarrollar una infraestructura que contribuyera a mejorar la salud individual y poblacional, y diera soporte a la investigación, siendo respetuosa con la privacidad, la seguridad y la ética.
Otros perfiles profesionales de creciente protagonismo en este tipo de proyectos son el delegado de protección de datos establecida en el RGPD, el responsable de gobernanza31 y el Chief Data Officer, que está evolucionando a Chief Analytics Officer por la importancia creciente del componente analítico de los datos34.
El uso secundario de datos clínicos2, las herramientas de Business Intelligence35 y el Big Data20 generan nuevos retos; entre ellos, la gobernanza, los estándares y la calidad de los datos, su volumen, disponibilidad y visualización, los métodos de análisis y el personal cualificado para ello, el impacto clínico, y la seguridad y la privacidad.
Este trabajo ha mostrado cómo en un servicio regional de salud es posible conectar registros de diversos silos de información, lo que abre nuevas posibilidades en el análisis de sus datos.
La digitalización de los servicios sanitarios está generando un volumen de datos sin precedentes, tanto para la atención sanitaria como para su uso secundario. Estos datos están dispersos, por lo que su disponibilidad es limitada.
¿Qué añade el estudio realizado a la literatura?El estudio muestra que es posible la conexión sistemática de registros sanitarios y ponerlos a disposición de múltiples usuarios para su uso con finalidades diversas; se abren nuevas posibilidades en el uso secundario de los datos.
Carlos Álvarez-Dardet.
Declaración de transparenciaEl autor principal (garante responsable del manuscrito) afirma que este manuscrito es un reporte honesto, preciso y transparente del estudio que se remite a Gaceta Sanitaria, que no se han omitido aspectos importantes del estudio, y que las discrepancias del estudio según lo previsto (y, si son relevantes, registradas) se han explicado.
Contribuciones de autoríaD. Muñoyerro-Muñiz y J.A. Goicoechra-Salazar: concepción y diseño del estudio, y revisión crítica. F.J. García-León: análisis e interpretación de los datos y escritura del artículo. A. Laguna-Téllez: codificación automática de los diagnósticos y revisión crítica. D. Larrocha-Mata y M. Cardero-Rivas: gestión de bases de datos, cruce de registros y revisión crítica. Todas estas personas han aprobado la versión final del artículo.
AgradecimientosAgradecemos la colaboración de J. Trancoso Estrada, J. Rodríguez Herrera y M.R. Jiménez Romero por sus aportaciones en cuanto al CMBD y CIE; y a V.D. Canto Casasola por su apoyo estadístico.
FinanciaciónNinguna.
Conflicto de interesesNinguno.











