



Infant size at birth is a useful indicator to evaluate fetal growth in relation to gestational age. There is no standard model to create anthropometric reference curves in neonates, but the method chosen could determine the reference values estimated. We describe the methods used to construct population-based reference curves of birth weight for gestational age in Catalonia, Spain. These methods included detection of implausible values of birth weight for gestational age by a probabilistic cluster model, utilization of the Generalized Additive Model for Location and Scale method to obtain smoothed percentiles and z-scores, and calculation of 95% confidence intervals by bootstrapping. To our knowledge, these are the first reference curves in neonates constructed through a method allowing asymmetric distributions with kurtosis to be modelled. Estimation of confidence intervals is useful to determine which reference intervals can be employed to assess newborn size.
La evaluación del tamaño en el nacimiento es un indicador útil para evaluar el crecimiento fetal en relación con la edad gestacional. No hay un modelo estándar para crear curvas de referencia antropométricas en recién nacidos, pero el método escogido podría determinar los valores de referencia estimados. Describimos los métodos utilizados para elaborar las curvas de referencia poblacionales del peso al nacer según la edad gestacional en Cataluña, España. Estos métodos incluyen la detección de los valores inverosímiles de peso al nacer para la edad gestacional mediante un modelo probabilístico de agrupaciones, la utilización del modelo Generalized Additive Model for Location and Scale para la obtención de los percentiles alisados, y las puntuaciones z y el cálculo de los intervalos de confianza del 95% mediante remuestreos. Hasta donde conocemos, éstas son las primeras curvas de referencia en recién nacidos en las cuales se ha utilizado un método que permite modelar distribuciones asimétricas con curtosis. La valoración de intervalos de confianza es útil para determinar los intervalos de referencia que pueden emplearse para evaluar el tamaño del recién nacido.
Birth weight by gestational age is recommended by the World Health Organization (WHO) as an indicator to assess the infant size at birth, prenatal and postnatal health.1 To obtain this indicator, reference curves and tables which relates birth weight to gestational age must be developed. Since 1947, when the first such curves were made in Birmingham2 a variety of curves have been published. These curves are not comparable due to the varying characteristics of the populations used to construct them but also due to differences in methodology as source of information (hospital versus population registry), exclusion criteria (congenital malformations, maternal diseases, implausible values, etc.), stratum of references (sex, ethnicity, multiplicity, etc.) and the statistical methods used to estimate reference values.3 There is not a standard model to create reference curves, but it is generally agreed that inclusion of all live births, including newborns with health problems, and the use of basedpopulation data assures the generalization of the curves.3 On the other hand, there is much variability in the statistical methods that are used for obtaining the reference values. Furthermore, it is important to have present that the chosen method can overestimate or underestimate the percentiles flattened.4
The objective is to describe the methods used to elaborate the population reference curves of birth weight for gestational age of Catalonia, Spain,5 using a methodology never used before in the published curves in our country.
The references we constructed were based on population data. The reference population was all alive births from mother residents in Catalonia during the period 1997–2001 (n=301,241). The source of information was the birth registry of Mother and Child Health Program of the Catalan Regional Government Department of Health. Data on birth was collected from hospital records in the screening of congenital metabolopathies and cystic fibrosis in all newborns that it is carried out in the first 72h of life.6
The variables used were: birth weight (in grams), gestational age (in weeks), sex, multiple pregnancy (yes/no) and year of birth. We assigned the multiple newborns to a twin or triplet pregnancy by conducting various recordlinkages using identifier variables. Reference curves were stratified by sex for singleton and twin births, but not for triplets due to the small number of cases. All registries with valid birth weight, gestational age and sex were included. Only were excluded those newborns classified as multiple pregnancy in which the siblings could not be identified by the record linkage or those in which the registries showed implausible values of birth weight for gestational age.
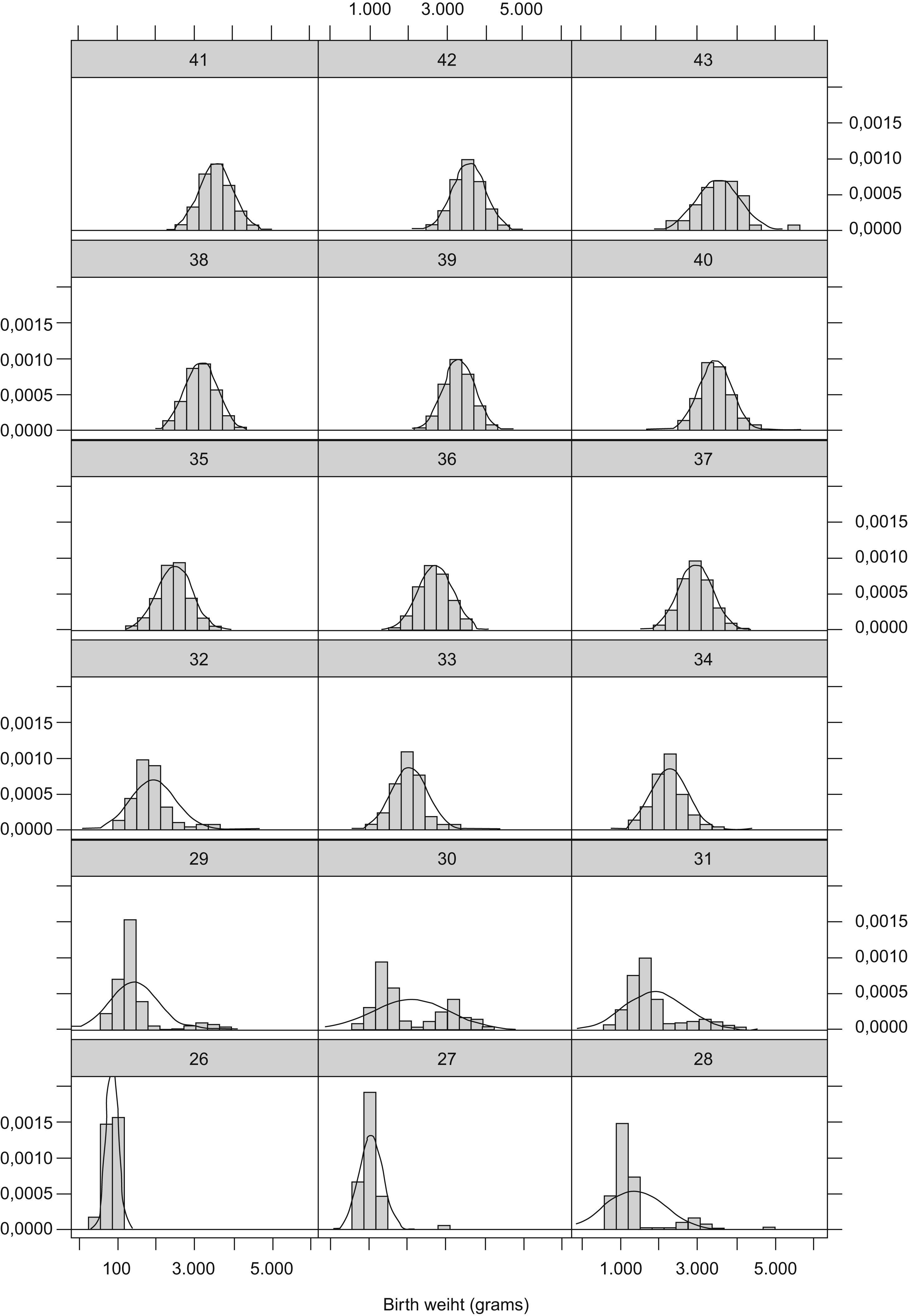
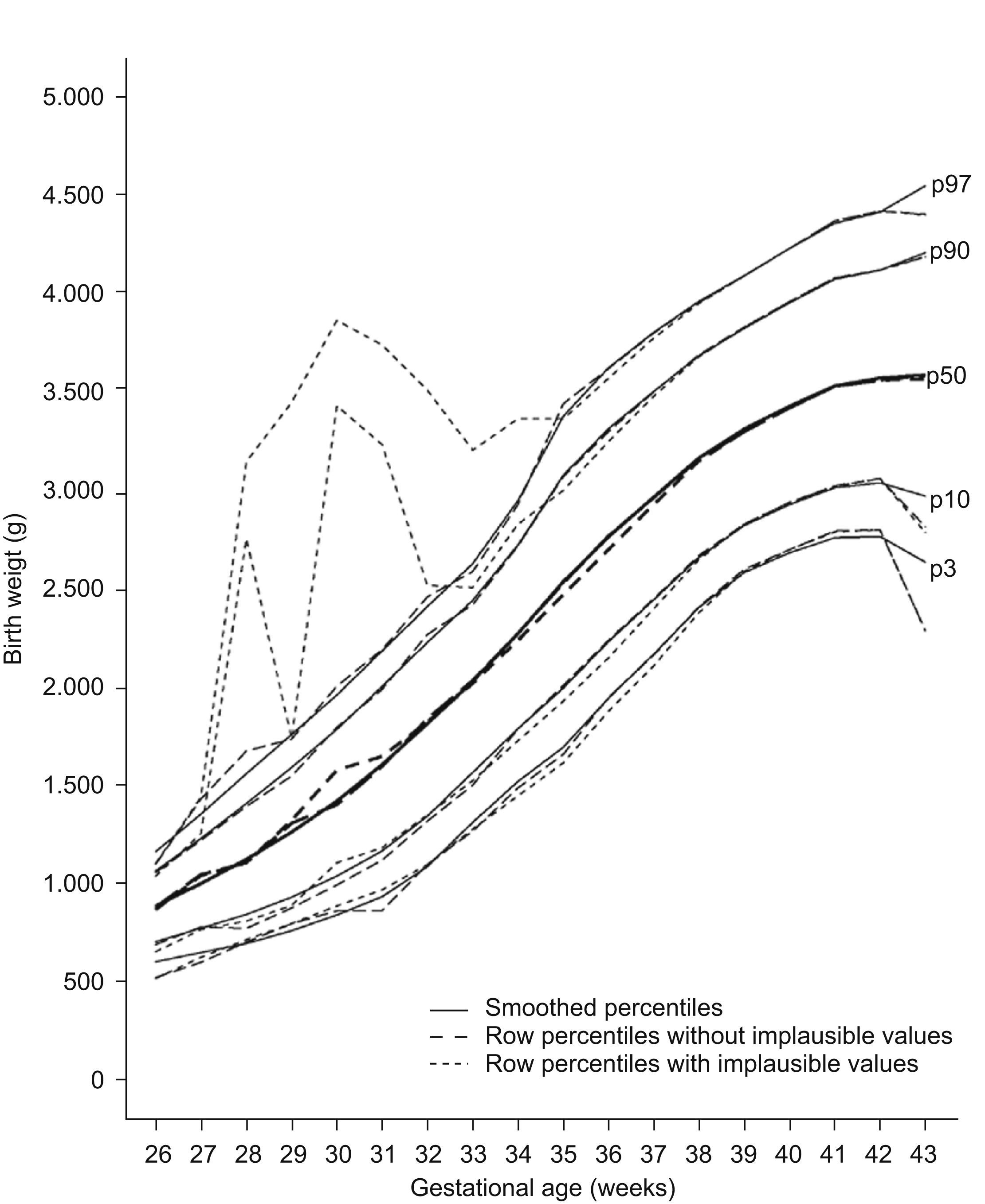
Implausible values for gestational age are due to systematic or random errors in the determination of the date of the last menstruation that could distort the upper percentiles of the reference curves if them not be removed.7 There are different methods to detect and to eliminate these erroneous values. In a basic way, some methods are based in the utilization of cutpoints from which the values would be considerate implausible and other in the utilization of statistical methods of probability assignment to this values.7 We chose a probabilistic cluster model to detect these implausible values because do not make any assumption about types of error were occurring in the data.8 The distributions of birth weight for early gestational ages were positively skewed and clearly bimodal between 30–32 weeks of gestation which suggested that data were not homogeneous (Fig. 1). The positively skewed and bimodal distributions of data suggested that they were a normal mixture distribution with two components.8 The hypothesis is that major component consisted of values of birth weight with greatest probability of belonging to the corresponding gestational age and the minor component for the values wrongly assigned to it. This method was used for gestational ages ranging from 26–34 weeks because in this range it was observed asymmetry and/or bimodality. After 34 week of gestation asymmetry disappeared. Birth weight value was considered implausible for the gestational age if the probability of belonging to the minor component was greater than 0.5 as used Tentoni et al.8 We also considered that to have more than 50% probability of being mistaken were sufficient to considered that the birth weight were erroneously assigned to the corresponding gestational age. The implausible values detected were 21.7% (n=1565) of the 7212 cases in this range. However, 9.8% (n=705) values were finally excluded, as they presented probabilities greater than 0.5 of belonging to the minor component. The implausible values detected by the probabilistic cluster model were similar to the data finally excluded between 26th and 32th weeks of gestation. The difference were greater in 33th and 34th gestational ages: 15.9% detected vs. 6.0% excluded in 33th gestational age and 30.27% detected vs. 5.74% excluded in 34th gestational age. These was due because their bimodal distribution were more overlapping, but we considered that asymmetry were sufficiently greater to considered that their distributions had two components. Furthermore, implausible values excluded in each week of gestation in this study were similar with the values obtained in the study by Tentoni et al8 which also observed a maximum of cases excluded in week 30 (32.21% our study vs 26.9% by Tentoni). Once implausible values have been removed the smoothed curves showed more biological plausibility (Fig. 2). The statistical package used was the EM-clust library via S-Plus version 6.1.


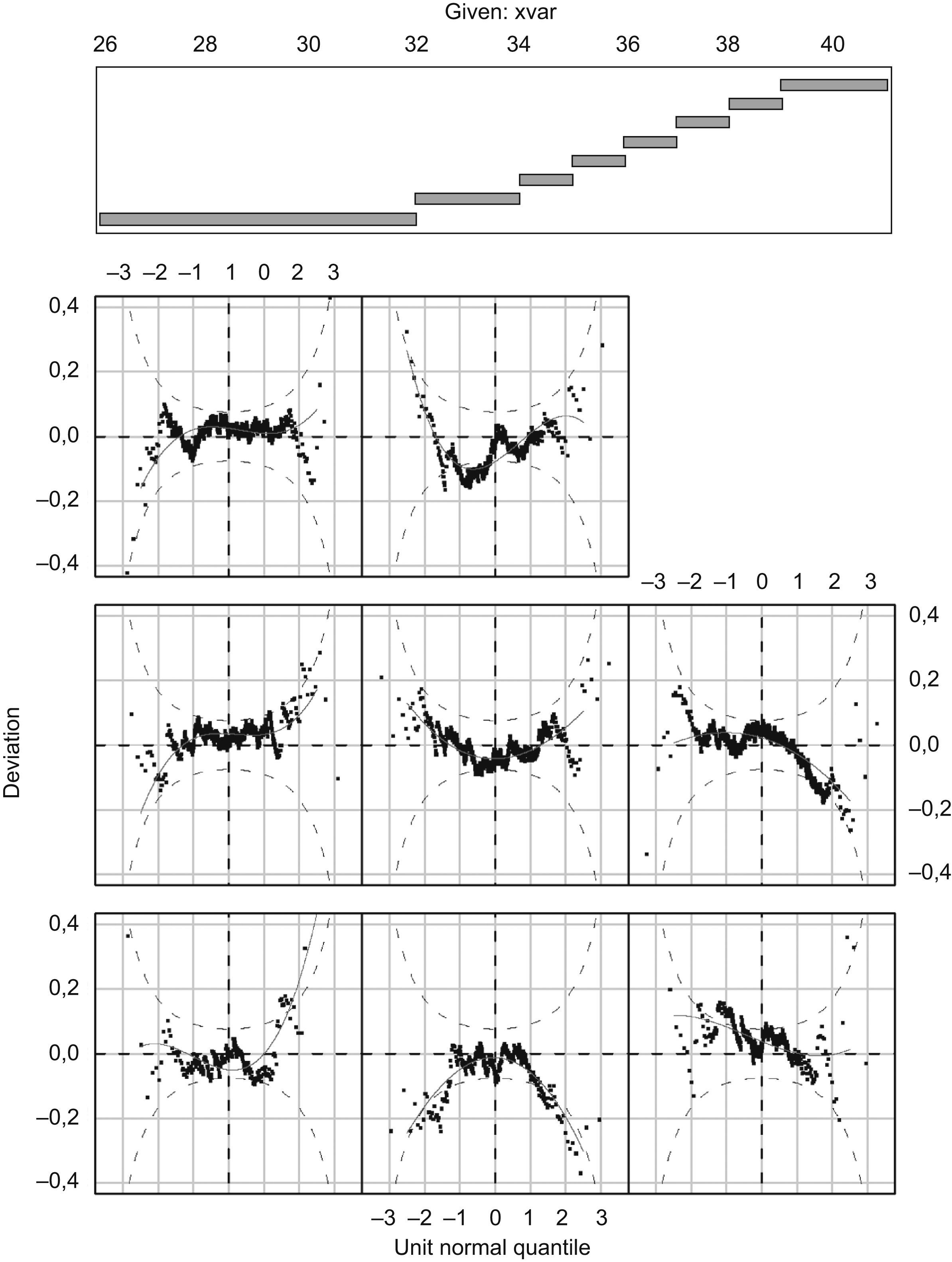
After removing implausible values, we have to choose the method for obtaining the reference values. The simplest form is to obtain the crude percentiles without applying any method of smoothing, but even if the sample size is great the obtained percentiles would be robust. Then to be able to obtain flattened curves it is necessary to apply statistical methods of smoothing, but which? In a basic way there are two family of methods, the non parametric methods and the parametric ones. The first do not make any assumption in the type of probability distribution of the birth weight at gestational age, giving in general percentiles less precise than the parametric methods.9 The parametric methods assume that the birth weight distribution for every week of gestational age follows the normal probability distribution. If we choose a parametric method, first we will determine if the probability distribution of weight for every gestational age is normal or not. If it is not normal, we will choose which transformation (logarithmic, Box-Cox, exponential, etc.) will be necessary to transform it to a normal distribution. We chose the Generalized Additive Model for Location and Scale Shape (GAMLSS) model because which allowed to model asymmetric distributions with kurtosis, to estimate any smoothed percentile values and the corresponding z-score.10 Other similar methods, such as the socalled LMS method,11 does not permit modelling kurtosis and hence, the estimated percentiles could be affected since the assumption of normality should not be fully satisfied. As far as we know, the GAMLSS method was used in the child growth standards developed by WHO12 but not in any other study obtaining newborn reference curves. This model allows to model the parameters of many distributions, like Normal distribution, Box-Cox distribution, exponential power distribution and Box-Cox-power-exponential (BCPE) distribution, among others. In our case we had chosen the BCPE distribution because it provided a model for variables with positive/negative skewness, and with leptokurtosis/platykurtosis, as in our study. Another reason was the minor deviance of the BCPE distribution compared with other distributions, indicating that it presented a better adjustment to our datum. The distribution has four parameters and expresses like BCPE (μ, σ, V, T). These parameters μ, σ, V, T are the parameters of location (median), dispersion (coefficient of variation), skewness (power of Box-Cox to transform the positive or negative assymetry) and kurtosis (exponential power to transform the lepto/platicurtosis). The assumption of the model is that once carried out the BoxCox and exponential transformations, the original variable will distribute according to the Normal distribution with median 0, standard deviation 1, assimetry 0 and kurtosis 3. The functions of each of the parameters are: g1(μ)=h1(x), g2(σ)=h2(x), g3(V)=h3(x) and g4(T)=h4(x). The left part of the function of each parameter indicates the link function which the parameter will be modelled, that it can be modelled in the original units or in transformed units like logarithm in basis 10, as in our study. The right part of the function are the non parametric functions cubic splines. The different non parametric functions are estimated by maximizing the penalized likelihood through the Fisher algorithm. The general criterion to select the model is to choose that minimize the GAIC («generalized Akaike Information Criterion»). From the estimation of the 4 parameters the model GAMLSS allows to obtain any percentile value with their corresponding zscore. The different models chose for log (birthweight) were: BCPE (10,11,6,7) for male singleton birth; BCPE (10,8,6,6) for female singleton birth; BCPE (3,2,1, CONSTANT) for twin, male sex; BCPE (3,0,0,0) for twin, female sex and BCPE (6,0,0, CONSTANT) for triplets. Q-test and wormplot (Fig. 3) methods check the assumptions of normality of the GAMLSS models by the assessment of deviation from normality of the z-scores in different contiguous gestational age groups. When the fit poorly it was repeated, increasing the parameters degrees of freedom in an attempt to improve the fit.10 In our study, all the models for singleton and twin pregnancies fitted well because the normality of zscores was satisfied. Thus, the different percentiles obtained are comparable to the corresponding standardized normal z-scores. Regarding the model for triplets, the degree to which normality assumptions are satisfied must be considered with caution, due to the small number of cases, something which may affect not only the estimations of percentiles but also the power of the various tests. The statistical package used was the GAMLSS library via R version 2.0.1.

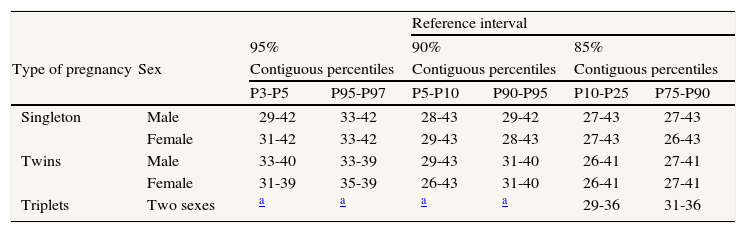
Finally, when the percentiles and z-scores are estimated, is important to obtain the 95% confidence intervals to determine their precision. To obtain the confidence intervals for the percentiles, 25 bootstraps11 with replacement were carried out for each of the groups. New models were fitted for each of the bootstraps with the same degrees of freedom as the respective original models, in order to ensure that the degree of smoothing was the same. The percentiles obtained were ordered, and the maximum and minimum values represent an approximate 95% confidence interval.11 The appraisal of the overlap of the limits of the 95% confidence intervals of the adjacent extreme percentiles permit to describe which percentiles it could be use to assess if a newborn are small or great for gestational age, and consequently, which reference interval could be used: 80% (percentile 10 to 90), 90% (percentile 5 to 95) and 95% (percentile 3 to 97). The precision estimated permit to use a 80%, 90% or 95% singleton and twin reference intervals in almost all weeks of gestation with a confidence of 95% that a newborn classified as small for gestational age really are allocated below and not above 10th percentile in the 80% reference interval for example (Table 1). We are not aware of any other study assessing precision and non-overlapping of 95% confidence intervals of percentiles, although various authors have recommended it.9,11 Instead of presenting 95% confidence intervals, other studies have reported percentile curves guaranteeing precision above certain minimum numbers of cases in each week of gestation and strata.13
Range of weeks of gestation which not overlap 95% confidence intervals of contiguous percentiles that limit reference intervals of 95% (p3-p97), 90% (p5-p95) and 85% (p10-p90), by pregnancy and sex
| Reference interval | |||||||
| 95% | 90% | 85% | |||||
| Type of pregnancy | Sex | Contiguous percentiles | Contiguous percentiles | Contiguous percentiles | |||
| P3-P5 | P95-P97 | P5-P10 | P90-P95 | P10-P25 | P75-P90 | ||
| Singleton | Male | 29-42 | 33-42 | 28-43 | 29-42 | 27-43 | 27-43 |
| Female | 31-42 | 33-42 | 29-43 | 28-43 | 27-43 | 26-43 | |
| Twins | Male | 33-40 | 33-39 | 29-43 | 31-40 | 26-41 | 27-41 |
| Female | 31-39 | 35-39 | 26-43 | 31-40 | 26-41 | 27-41 | |
| Triplets | Two sexes | a | a | a | a | 29-36 | 31-36 |
The methods used allows to obtain reference curves and tables population-based, statistical modelling of gestational ages to correct biologically implausible values, the sex-specific and multifetal pregnancy percentiles, the adaptability to the use of either percentiles or z-scores and the assessment of the precision of the extreme percentiles by the calculation of 95% confidence intervals. In conclusion, the methods used are applicable to develop newborn reference curves.
We are grateful for the collaboration of Dave MacFarlane for English translation and edition reviewing of the last manuscript version.
Financing
This manuscript was in part funded by the Mother and Child Programme of the Department of Health. Generalitat de Catalunya.











